
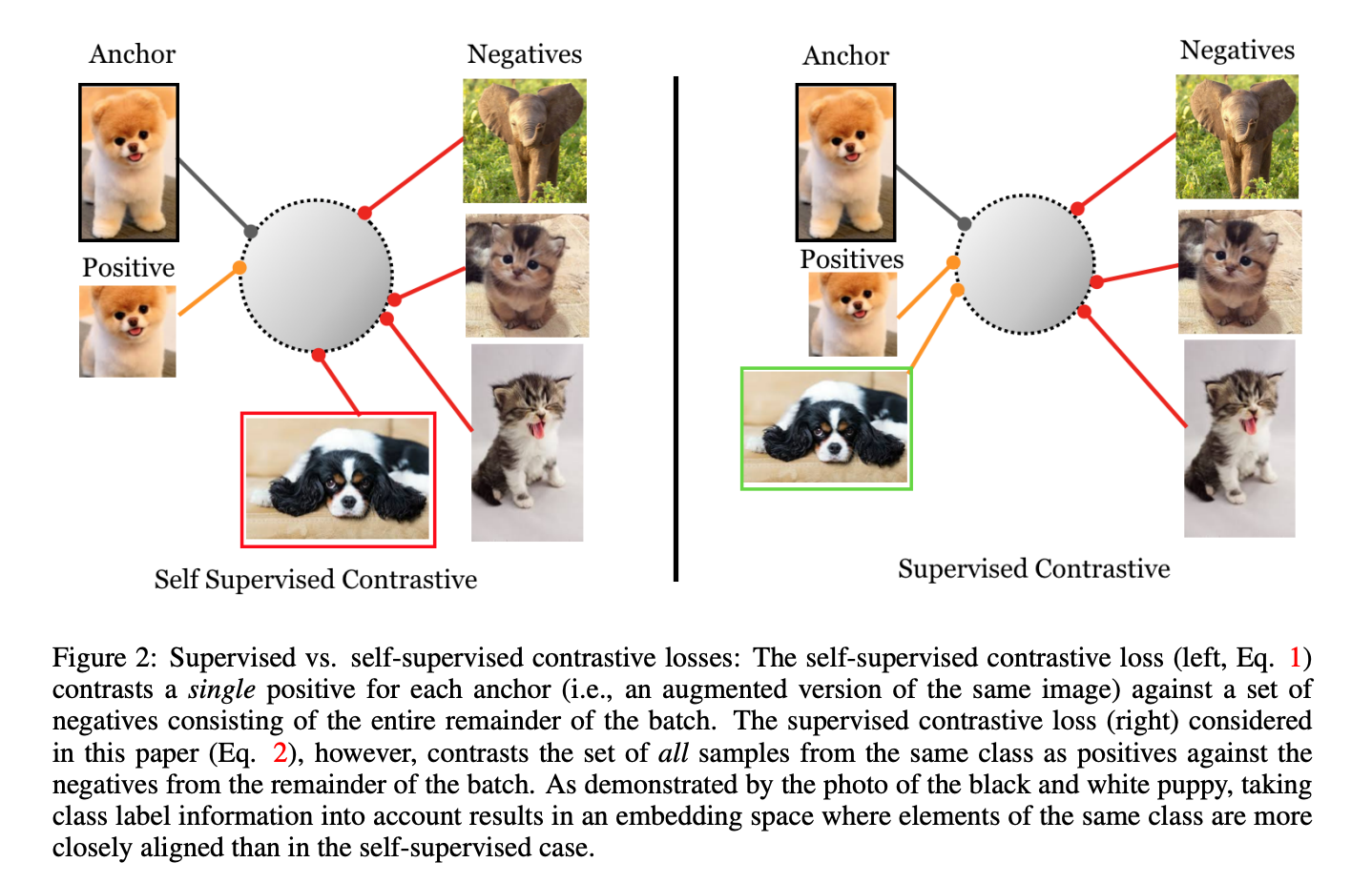
SupCon introduces a generalized form for contrastive losses, and shows that self-supervised loss from SimCLR, N-Pair loss and triplet margin loss are special cases. In this repo, we leverage this general form and formalize a loss that can transition from self-supervised contrastive loss to supervised contrastive loss:
$$ \begin{equation} \begin{split} \mathcal{L} & = \hspace{30mm} \mathcal{L}^{unsup} \hspace{16mm}+ \hspace{30mm} \lambda\mathcal{L}^{sup} \\ \\ & = - \sum_{i \in I} \log \frac{\exp \left(\boldsymbol{z}_{i} \cdot \boldsymbol{z}_{j(i)} / \tau\right)}{\sum_{a \in A(i)} \exp \left(\boldsymbol{z}_{i} \cdot \boldsymbol{z}_{a} / \tau\right)} + \lambda \sum_{i \in I} \frac{-1}{|P(i)|} \sum_{p \in P(i)} \log \frac{\exp \left(\boldsymbol{z}_{i} \cdot \boldsymbol{z}_{p} / \tau\right)}{\sum_{a \in A(i)} \exp \left(\boldsymbol{z}_{i} \cdot \boldsymbol{z}_{a} / \tau\right)} \end{split} \end{equation} $$We use supervised signal as regularization which has an associated weight $\lambda$, this allows to pretrain with a dataset mixed with labelled and unlabelled data. This regularization can help to learn more generic features which in turn can help with the downstream task. In SupCon callback you can choose to use all samples (UnsupMethod.All) for unsupervised loss or only use the ones doesn't have a label (UnsupMethod.All). Supervised loss will use the samples with labels.
Therefore, positive samples come form two disjoint categories:
(1) Other view of the anchor sample after augmentation (self-supervised case)
(2) All views of the samples that have the same class id with anchor, including the other view of the same sample (supervised case)
Note that self-supervised and unsupervised are used interchangably in this context
SimCLR model consists of an encoder and a projector (MLP) layer. The definition of this module is fairly simple as below.
Instead of directly using SupConModel by passing both an encoder and a projector, create_simclr_model function can be used by minimally passing a predefined encoder and the expected input channels.
You can use self_supervised.layers module to create an encoder. It supports all timm and fastai models available out of the box.
We define number of input channels with n_in, projector/mlp's hidden size with hidden_size, projector/mlp's final projection size with projection_size and projector/mlp's number of layers with nlayers.
encoder = create_encoder("tf_efficientnet_b0_ns", n_in=3, pretrained=False, pool_type=PoolingType.CatAvgMax)
model = create_supcon_model(encoder, hidden_size=2048, projection_size=128, nlayers=2)
out = model(torch.randn((2,3,224,224))); out.shape
The following parameters can be passed;
- aug_pipelines list of augmentation pipelines List[Pipeline] created using functions from
self_supervised.augmentationsmodule. EachPipelineshould be set tosplit_idx=0. You can simply useget_supcon_aug_pipelinesutility to get aug_pipelines. - temp temperature scaling for cross entropy loss (defaults to paper's best value)
SupCon algorithm uses 2 views of a given image, and SupCon callback expects a list of 2 augmentation pipelines in aug_pipelines.
You can simply use helper function get_supcon_aug_pipelines() which will allow augmentation related arguments such as size, rotate, jitter...and will return a list of 2 pipelines, which then can be passed to the callback. This function uses get_multi_aug_pipelines which then get_batch_augs. For more information you may refer to self_supervised.augmentations module.
Also, you may choose to pass your own list of aug_pipelines which needs to be List[Pipeline, Pipeline] where Pipeline(..., split_idx=0). Here, split_idx=0 forces augmentations to be applied in training mode.
aug_pipelines = get_supcon_aug_pipelines(size=28, rotate=False, jitter=False, bw=False, blur=False, stats=None, cuda=False)
aug_pipelines
supcon = SupCon([Pipeline([],0),Pipeline([],0)], unsup_class_id=0, unsup_method="all")
yb = torch.tensor([1,1,2,2])
pred = torch.randn((yb.shape[0]*2,128))
loss1 = supcon.unsup_lf(pred, yb)
nll = -(supcon._remove_diag(F.normalize(pred) @ F.normalize(pred).T)/supcon.temp).log_softmax(1)
loss2 = torch.mean(tensor([nll[i,idx] for i, idx in enumerate([3,4,5,6,0,1,2,3])]))
assert torch.isclose(loss1,loss2)
loss1 = supcon.sup_lf(pred, yb)
nll = -(supcon._remove_diag(F.normalize(pred) @ F.normalize(pred).T)/supcon.temp).log_softmax(1)
ohe = supcon._remove_diag(tensor([[1,1,0,0,1,1,0,0],
[1,1,0,0,1,1,0,0],
[0,0,1,1,0,0,1,1],
[0,0,1,1,0,0,1,1],
[1,1,0,0,1,1,0,0],
[1,1,0,0,1,1,0,0],
[0,0,1,1,0,0,1,1],
[0,0,1,1,0,0,1,1]]))
loss2 = (tensor([(row[idxs.bool()].sum()/idxs.sum()) for row, idxs in zip(nll, ohe)])).mean()
assert torch.isclose(loss1, loss2)
supcon = SupCon([Pipeline([],0),Pipeline([],0)], unsup_class_id=0, unsup_method="only")
yb = torch.tensor([1,1,2,2])
pred = torch.randn((yb.shape[0]*2,128))
loss1 = supcon.unsup_lf(pred, yb)
assert loss1 == 0
loss1 = supcon.sup_lf(pred, yb)
nll = -(supcon._remove_diag(F.normalize(pred) @ F.normalize(pred).T)/supcon.temp).log_softmax(1)
ohe = supcon._remove_diag(tensor([[1,1,0,0,1,1,0,0],
[1,1,0,0,1,1,0,0],
[0,0,1,1,0,0,1,1],
[0,0,1,1,0,0,1,1],
[1,1,0,0,1,1,0,0],
[1,1,0,0,1,1,0,0],
[0,0,1,1,0,0,1,1],
[0,0,1,1,0,0,1,1]]))
loss2 = (tensor([(row[idxs.bool()].sum()/idxs.sum()) for row, idxs in zip(nll, ohe)])).mean()
assert torch.isclose(loss1,loss2)
yb = torch.tensor([0,0,0,0])
pred = torch.randn((yb.shape[0]*2,128))
supcon = SupCon([Pipeline([],0),Pipeline([],0)], unsup_class_id=0, unsup_method="all")
loss1 = supcon.unsup_lf(pred, yb)
supcon = SupCon([Pipeline([],0),Pipeline([],0)], unsup_class_id=0, unsup_method="only")
loss2 = supcon.unsup_lf(pred, yb)
nll = -(supcon._remove_diag(F.normalize(pred) @ F.normalize(pred).T)/supcon.temp).log_softmax(1)
loss3 = torch.mean(tensor([nll[i,idx] for i, idx in enumerate([3,4,5,6,0,1,2,3])]))
assert torch.isclose(loss1, loss2) and torch.isclose(loss2, loss3)
loss1 = supcon.sup_lf(pred, yb)
assert loss1 == 0
yb = torch.tensor([1,1,2,0])
pred = torch.randn((yb.shape[0]*2,128))
supcon = SupCon([Pipeline([],0),Pipeline([],0)], unsup_class_id=0, unsup_method="all")
loss1 = supcon.unsup_lf(pred, yb)
nll = -(supcon._remove_diag(F.normalize(pred) @ F.normalize(pred).T)/supcon.temp).log_softmax(1)
loss2 = torch.mean(tensor([nll[i,idx] for i, idx in enumerate([3,4,5,6,0,1,2,3])]))
assert torch.isclose(loss1, loss2)
supcon = SupCon([Pipeline([],0),Pipeline([],0)], unsup_class_id=0, unsup_method="only")
loss1 = supcon.unsup_lf(pred, yb)
assert loss1 == 0 # log(1) -> 0, there is no negative sample
loss1 = supcon.sup_lf(pred, yb)
targ = torch.cat([yb,yb])
unsup_mask = (targ == supcon.unsup_class_id)
pred = pred[~unsup_mask]
nll = -(supcon._remove_diag(F.normalize(pred) @ F.normalize(pred).T)/supcon.temp).log_softmax(1)
ohe = supcon._remove_diag(tensor([[1,1,0,1,1,0],
[1,1,0,1,1,0],
[0,0,1,0,0,1],
[1,1,0,1,1,0],
[1,1,0,1,1,0],
[0,0,1,0,0,1]]))
loss2 = (tensor([(row[idxs.bool()].sum()/idxs.sum()) for row, idxs in zip(nll, ohe)])).mean()
assert torch.isclose(loss1, loss2)
The following parameters can be passed;
- aug_pipelines list of augmentation pipelines List[Pipeline] created using functions from
self_supervised.augmentationsmodule. EachPipelineshould be set tosplit_idx=0. You can simply useget_supcon_aug_pipelinesutility to get aug_pipelines. - temp temperature scaling for cross entropy loss (defaults to paper's best value)
SupCon algorithm uses 2 views of a given image, and SupCon callback expects a list of 2 augmentation pipelines in aug_pipelines.
You can simply use helper function get_supcon_aug_pipelines() which will allow augmentation related arguments such as size, rotate, jitter...and will return a list of 2 pipelines, which then can be passed to the callback. This function uses get_multi_aug_pipelines which then get_batch_augs. For more information you may refer to self_supervised.augmentations module.
Also, you may choose to pass your own list of aug_pipelines which needs to be List[Pipeline, Pipeline] where Pipeline(..., split_idx=0). Here, split_idx=0 forces augmentations to be applied in training mode.
from fastai.test_utils import *
class ContrastiveModel(Module):
def __init__(self):
self.encoder = nn.Parameter(tensor([1.]))
self.projector = nn.Linear(1,5, bias=False)
self.projector.weight.data.zero_()
self.projector.weight.data += 1
self.projector = nn.Sequential(self.projector)
def forward(self, x): return self.projector(x*self.encoder)
supcon = SupConMOCO([Pipeline([noop],0),Pipeline([noop],0)], unsup_class_id=0, unsup_method="all", K=8, m=0.999, reg_lambda=1.0, temp=0.07)
yb = torch.tensor([1,1,2,2])
pred = torch.randn((yb.shape[0]*2,128))
learner = synth_learner(cbs=supcon, data=synth_dbunch(a=0,b=0,bs=4), model=ContrastiveModel())
learner.sup_con_moco.aug1, learner.sup_con_moco.aug2
learner.sup_con_moco.__dict__['__stored_args__']
learner('before_fit')
assert learner.sup_con_moco.emb_queue.shape == (8,5)
assert torch.all(learner.sup_con_moco.label_queue == torch.zeros(8))
assert not any(list(o.requires_grad for o in learner.sup_con_moco.encoder_k.parameters()))
assert torch.all(learner.sup_con_moco.encoder_k.projector[0].weight == 1)
b = tensor([1,1,-1,1]).reshape(-1,1),tensor([1,1,2,2])
learner._split(b)
learner('before_batch')
key_embs, labels = learner.sup_con_moco.yb
assert torch.equal(F.normalize(learner.sup_con_moco.encoder_k(b[0])), key_embs)
assert torch.equal(labels, b[1])
learner.model.encoder.data += 0.1 # pseudo param update 1.0 -> 1.1
learner.model.projector[0].weight.data += 0.1 # pseudo param update 1.0 -> 1.1
learner('after_step')
assert torch.equal(learner.sup_con_moco.emb_queue[:4], key_embs)
newval = 1*supcon.m + 1.1*(1-supcon.m)
assert torch.all(learner.sup_con_moco.encoder_k.encoder.data == newval) and torch.all(learner.sup_con_moco.encoder_k.projector[0].weight.data==newval)
b = tensor([-1,-1,1,-1]).reshape(-1,1),tensor([1,1,2,2])
learner._split(b)
learner('before_batch')
key_embs, labels = learner.sup_con_moco.yb
assert torch.equal(F.normalize(learner.sup_con_moco.encoder_k(b[0])), key_embs)
assert torch.equal(labels, b[1])
learner('after_step')
assert torch.equal(learner.sup_con_moco.emb_queue[-4:], key_embs)
assert torch.equal(learner.sup_con_moco.label_queue, tensor([1,1,2,2,1,1,2,2]).float())
newval = newval*supcon.m + 1.1*(1-supcon.m)
assert torch.all(learner.sup_con_moco.encoder_k.encoder.data == newval) and torch.all(learner.sup_con_moco.encoder_k.projector[0].weight.data==newval)
pred = F.normalize(learner.model(learner.x))
loss1 = learner.sup_con_moco.unsup_lf(pred, *learner.yb)
key_embs, labels = learner.yb
logits = pred @ torch.cat([key_embs,learner.sup_con_moco.emb_queue]).T / learner.sup_con_moco.temp
loss2 = F.cross_entropy(logits, tensor([0,1,2,3]))
assert loss1 == loss2
learner.sup_con_moco.unsup_method = UnsupMethod.Only
learner.sup_con_moco.unsup_class_id = 1
loss1 = learner.sup_con_moco.unsup_lf(pred, *learner.yb)
logits = pred[labels==1] @ torch.cat([key_embs[labels==1],learner.sup_con_moco.emb_queue[learner.sup_con_moco.label_queue==1]]).T / learner.sup_con_moco.temp
loss2 = F.cross_entropy(logits, tensor([0,1]))
assert loss1 == loss2
learner.sup_con_moco.unsup_class_id = 0
pred = F.normalize(learner.model(learner.x))
loss1 = learner.sup_con_moco.sup_lf(pred, *learner.yb)
logits = pred @ torch.cat([key_embs,learner.sup_con_moco.emb_queue]).T / learner.sup_con_moco.temp
ohe_labels = tensor([[1., 1., 0, 0, 1., 1., 0, 0, 1., 1., 0, 0],
[1., 1., 0, 0, 1., 1., 0, 0, 1., 1., 0, 0],
[0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1,],
[0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1]])
loss2 = (F.cross_entropy(logits, ohe_labels, reduction='none') / ohe_labels.sum(1)).mean()
assert loss1 == loss2
learner.sup_con_moco.unsup_class_id = 2
pred = F.normalize(learner.model(learner.x))
loss1 = learner.sup_con_moco.sup_lf(pred, *learner.yb)
logits = pred[labels != 2] @ torch.cat([key_embs[labels != 2],learner.sup_con_moco.emb_queue[learner.sup_con_moco.label_queue != 2]]).T / learner.sup_con_moco.temp
ohe_labels = tensor([[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]])
loss2 = (F.cross_entropy(logits, ohe_labels, reduction='none') / ohe_labels.sum(1)).mean()
assert loss1 == loss2
key_embs, labels = learner.yb
learner.sup_con_moco.unsup_class_id = 3
learner.xb = (torch.cat([learner.x, tensor([[0]])]),)
key_embs, labels = torch.cat([learner.y[0], learner.y[0][:1]]), torch.cat([learner.y[1], tensor([3])])
learner.yb = (key_embs, labels)
pred = F.normalize(learner.model(learner.x))
loss1 = learner.sup_con_moco.sup_lf(pred, *learner.yb)
logits = pred[labels != 3] @ torch.cat([key_embs[labels != 3],learner.sup_con_moco.emb_queue[learner.sup_con_moco.label_queue != 3]]).T / learner.sup_con_moco.temp
ohe_labels = tensor([[1., 1., 0, 0, 1., 1., 0, 0, 1., 1., 0, 0],
[1., 1., 0, 0, 1., 1., 0, 0, 1., 1., 0, 0],
[0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1,],
[0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1]])
loss2 = (F.cross_entropy(logits, ohe_labels, reduction='none') / ohe_labels.sum(1)).mean()
assert loss1 == loss2
key_embs, labels = learner.yb
learner.sup_con_moco.unsup_class_id = 3
learner.xb = (torch.cat([learner.x[:2],tensor([[0]]), learner.x[2:]]),)
key_embs, labels = torch.cat([learner.y[0][:2], learner.y[0][:1], learner.y[0][2:]]), torch.cat([learner.y[1][:2], tensor([3]), learner.y[1][2:]])
learner.yb = (key_embs, labels)
pred = F.normalize(learner.model(learner.x))
loss1 = learner.sup_con_moco.sup_lf(pred, *learner.yb)
logits = pred[labels != 3] @ torch.cat([key_embs[labels != 3],learner.sup_con_moco.emb_queue[learner.sup_con_moco.label_queue != 3]]).T / learner.sup_con_moco.temp
ohe_labels = tensor([[1., 1., 0, 0, 1., 1., 0, 0, 1., 1., 0, 0],
[1., 1., 0, 0, 1., 1., 0, 0, 1., 1., 0, 0],
[0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1,],
[0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1]])
loss2 = (F.cross_entropy(logits, ohe_labels, reduction='none') / ohe_labels.sum(1)).mean()
assert loss1 == loss2
path = untar_data(URLs.IMAGEWANG_160)
items = get_image_files(path)
items = np.random.choice(items, size=1000)
tds = Datasets(items, [[PILImage.create, ToTensor, RandomResizedCrop(112, min_scale=1.)],
[parent_label, Categorize()]], splits=RandomSplitter()(items))
dls = tds.dataloaders(bs=5, after_item=[ToTensor(), IntToFloatTensor()], device='cpu')
unsup_class_id = dls.vocab.o2i['unsup']
fastai_encoder = create_encoder('xresnet18', n_in=3, pretrained=False)
model = create_supcon_model(fastai_encoder, hidden_size=2048, projection_size=128)
aug_pipelines = get_supcon_aug_pipelines(size=28, rotate=False, jitter=False, bw=False, blur=False, stats=None, cuda=False)
learn = Learner(dls, model, cbs=[SupCon(aug_pipelines,
unsup_class_id,
unsup_method=UnsupMethod.All, reg_lambda=1.0, temp=0.07,
print_augs=True),ShortEpochCallback(0.001)])
Also, with show_one() method you can inspect data augmentations as a sanity check. You can use existing augmentation functions from augmentations module.
b = dls.one_batch()
learn._split(b)
learn('before_batch')
axes = learn.sup_con.show(n=5)

learn.fit(1)
learn.recorder.losses
fastai_encoder = create_encoder('xresnet18', n_in=3, pretrained=False)
model = create_supcon_model(fastai_encoder, hidden_size=2048, projection_size=128)
aug_pipelines = get_supcon_aug_pipelines(size=28, rotate=False, jitter=False, bw=False, blur=False, stats=None, cuda=False)
learn = Learner(dls, model, cbs=[SupConMOCO(aug_pipelines,
unsup_class_id,
unsup_method=UnsupMethod.All, K=25, reg_lambda=1.0, temp=0.07,
print_augs=True),ShortEpochCallback(0.001)])
learn.fit(1)